여름은 무더위의 계절이지만 학회의 계절이기도 합니다. 검색 및 데이터 사이언스 분야의 메이저 학회인 KDD’21와 SIGIR’21이 최근 마무리되었습니다. 온라인 학회라는 특성상 새로운 곳을 방문하고 사람들과 교류하는 경험을 할 수는 없지만 새로운 지식과 연구 성과를 접하는 학회의 본질은 여전합니다.
학회를 최대한 잘 참석하는 방법?
DnA 팀원중 많은 분들이 SIGIR과 KDD에 참석하여 많은 배움을 얻었습니다. 특히 KDD의 경우에는 업무 관련 일정이나 미팅을 조정하여 정참석자들이 일주일동안 학회에 집중하실 수 있도록 하였습니다. 학회가 처음이신 팀원들을 위해 다음과 같은 가이드도 드렸습니다.

이를 요약하면 학회 초보는 튜토리얼 / 중급자는 논문 / 상급자는 워크샵에 집중하는 접근법입니다. 튜토리얼에서 해당 분야의 기초 지식을, 논문에서 최근에 보고된 연구 성과를, 워크샵에서 현재 진행중인 연구 성과를 확인할 수 있기 때문입니다.
키노트: 데이터 사이언스의 변화하는 본질
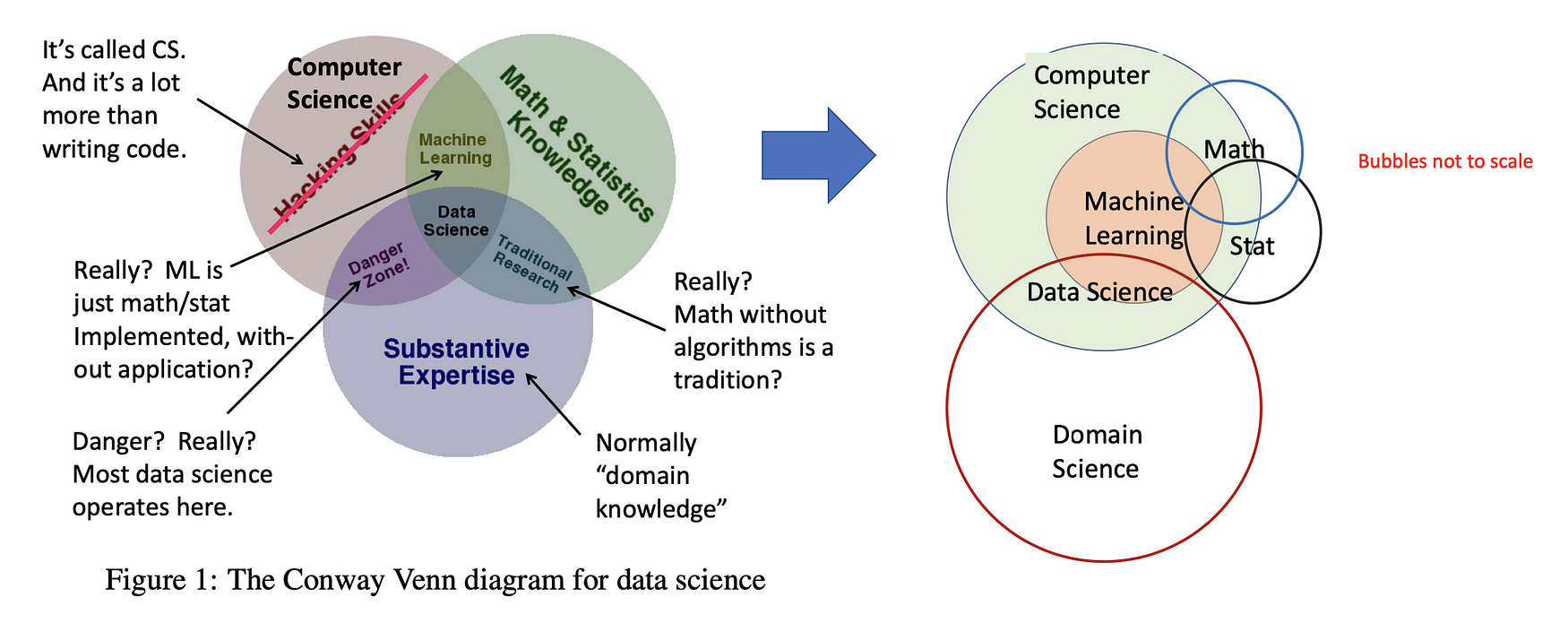
우선 인상적이었던 키노트는 스탠포드 인포랩의 Jeffrey D. Ullman 교수의 데이터 사이언스의 변화하는 본질에 관한 것이었습니다. 그는 학계의 관점에서 데이터 사이언스를 수학과 통계의 방법론을 기본으로 하는 CS와 기타 과학의 접점으로 설명합니다. 데이터 사이언스의 정의는 항상 논란을 가져오는 주제인데요, 좀 더 관심 있으신 분은 관련 아티클을 참고하시면 될 것 같습니다.
논문: 네트워크 상에서의 온라인(AB) 테스트
이번에는 페이스북에서 나온 네트워크 상에서의 온라인(AB) 테스트에 관한 논문을 소개합니다. 온라인 테스트는 실험 단위(보통 사용자) 간의 독립성을 가정하는데, 페이스북과 같은 소셜 네트워크에서 실험을 하다 보면 이런 전제가 깨지게 됩니다.
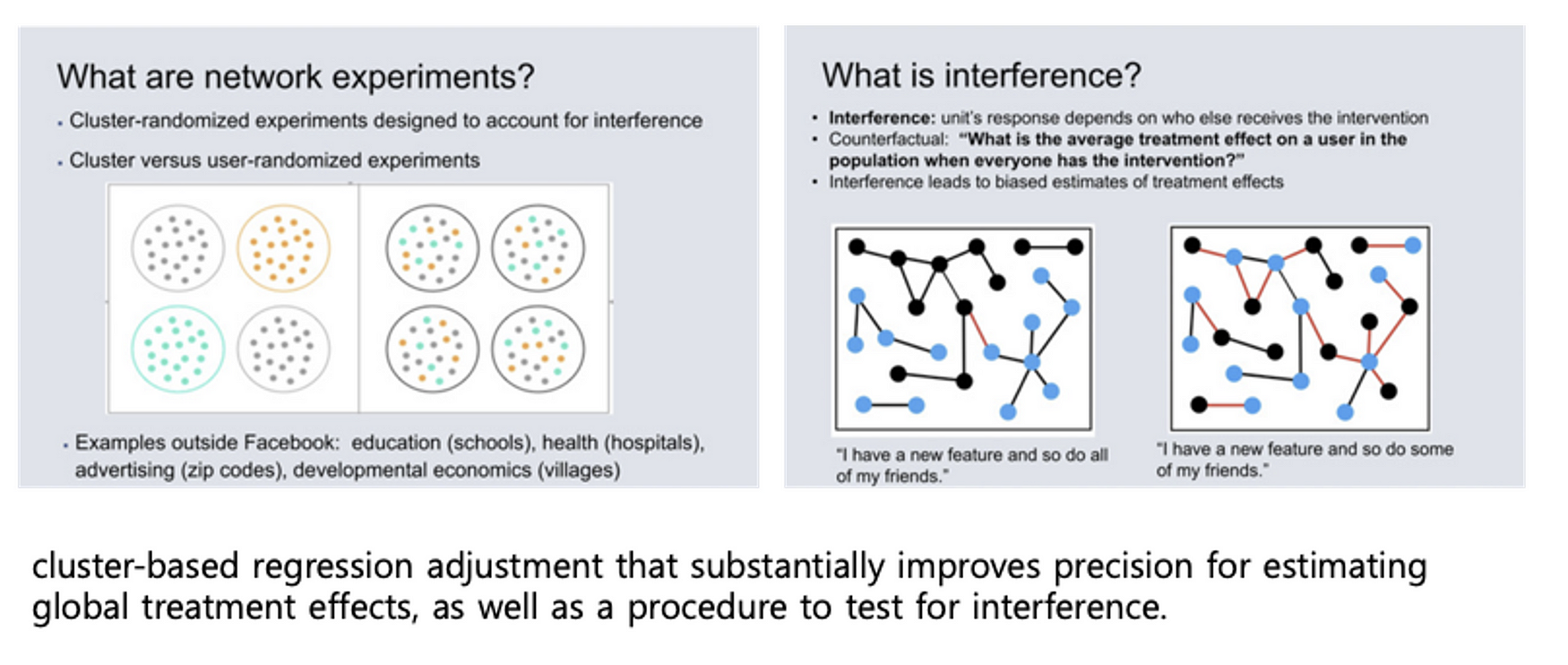
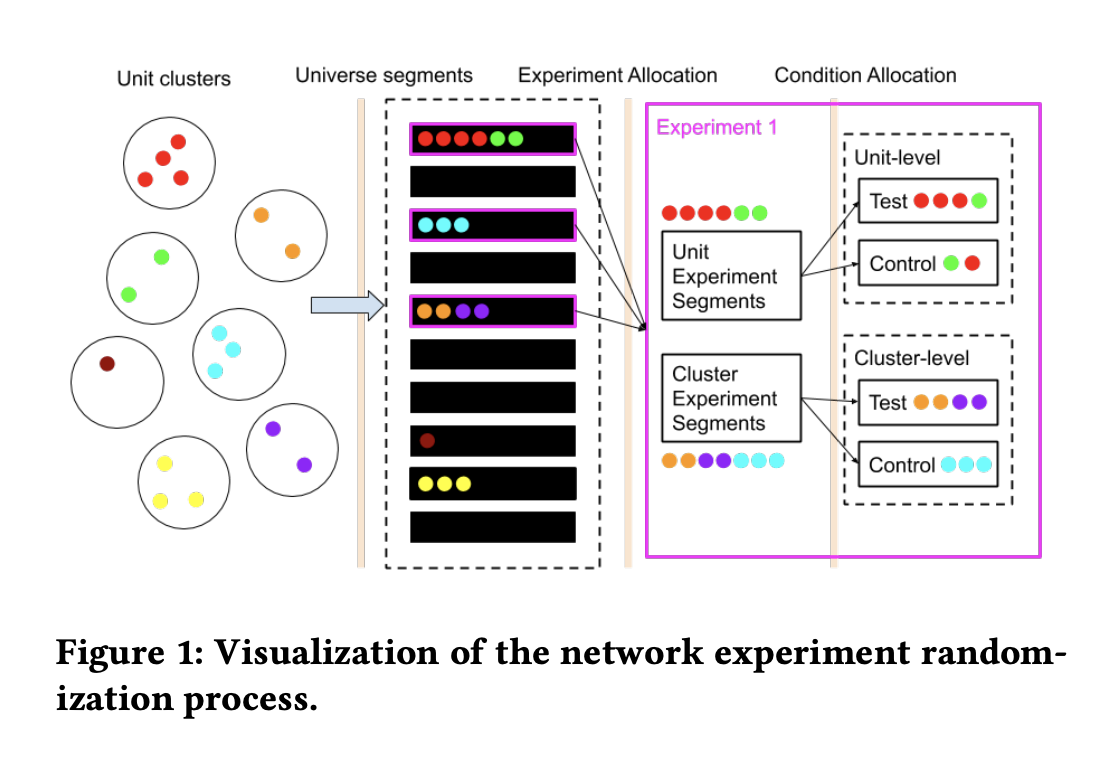
따라서 이런 환경 실험을 수행하고 올바른 결과를 얻기 위해서는 구성원간의 연결고리를 최소화해야 하는데, 본 논문에서는 이를 위한 방안으로 클러스터링을 제안하고 있습니다. 사용자간의 연관도를 가지고 클러스터링의 수행하고, 이 결과물을 기준으로 실험군을 구분하면 실험군 간의 간섭을 최소화할 수 있습니다. (아래 그림에 자세히 설명)
튜토리얼: Mixed Method Development of Evaluation Metrics
마지막으로 Spotify의 연구자들이 진행한 온라인 지표 개발에 대한 튜토리얼을 소개합니다. 대부분의 온라인 서비스에서는 지표에 대한 고민을 하게 되고, 보통 성숙한 온라인 테스트 환경에서는 의사결정에 수백~수천개의 지표를 사용하게 되는데, 본 튜토리얼에서는 사용자 연구와 데이터 분석을 결합한 지표 개발의 방법론을 소개하고 있습니다.

이렇게 수많은 지표 가운데 무엇이 서비스의 성공과 직결되는지는 실제로 많은 회사에서 고민하는 부분입니다. 본 튜토리얼에서는 방법론의 사례로 아래와 같이 Spotify에서 사용자의 성공과 연결되는 지표를 개발하고 평가한 과정을 소개하고 있습니다. 단순히 CTR 및 Top Position Click을 보던 방법에서 다양한 성공 지표를 정의하고 이를 통해 제품 개선에 좀더 민감하게 반응하는 성공 지표를 정의하였습니다.

결론: 학회는 성장하는 데이터 사이언티스트 / 엔지니어의 친구!
이번 포스팅에서는 최근 있었던 학회에서 DnA 팀의 주 연구 개발 분야에 관련된 컨텐츠를 살펴 보았습니다. 온라인 학회의 특성상 현장의 느낌을 살리기는 힘들지만, 더 많은 사람들이 학회 컨텐츠를 접할 수 있다는 장점이 있습니다.
성장을 원하는 데이터 사이언티스트 / 엔지니어분이라면 학회에 직접 참석하거나 홈페이지에 공개된 발표 내용을 온라인으로 보시는 것을 추천합니다. 그리고 조만간 DnA 팀의 연구 개발 성과를 이런 학회에서 공유하기를 기대해 봅니다!
(네이버 검색 DnA팀의 여정에 함께할 분께서는 DnA 팀블로그의 소개 페이지를 참조 바랍니다.)

